Advanced AI Models
Discover and use the world's most advanced AI models
Discover and use the world's most advanced AI models

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

The fastest image generation model tailored for local development and personal use
An 8 billion parameter language model from Meta, fine tuned for chat completions

Generate image captions
A 70 billion parameter language model from Meta, fine tuned for chat completions

Convert speech in audio to text

Return CLIP features for the clip-vit-large-patch14 model

A latent text-to-image diffusion model capable of generating photo-realistic images given any text input

Practical face restoration algorithm for *old photos* or *AI-generated faces*

A simple OCR Model that can easily extract text from an image.

A text-to-image generative AI model that creates beautiful images

Real-ESRGAN with optional face correction and adjustable upscale

Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification

Faster, better FLUX Pro. Text-to-image model with excellent image quality, prompt adherence, and output diversity.

Kokoro v1.0 - text-to-speech (82M params, based on StyleTTS2)
Base version of Llama 3, an 8 billion parameter language model from Meta.

Generate CLIP (clip-vit-large-patch14) text & image embeddings

Practical face restoration algorithm for *old photos* or *AI-generated faces*

Robust face restoration algorithm for old photos / AI-generated faces

Google's latest image editing model in Gemini 2.5

image tagger

Generate detailed images from scribbled drawings

A state-of-the-art text-based image editing model that delivers high-quality outputs with excellent prompt following and consistent results for transforming images through natural language

multilingual-e5-large: A multi-language text embedding model

This is the fastest Flux endpoint in the world.

A 12 billion parameter rectified flow transformer capable of generating images from text descriptions

Visual instruction tuning towards large language and vision models with GPT-4 level capabilities

Answers questions about images

High resolution image Upscaler and Enhancer. Use at ClarityAI.co. A free Magnific alternative. Twitter/X: @philz1337x

Detect everything with language!

Fill in masked parts of images with Stable Diffusion

whisper-large-v3, incredibly fast, powered by Hugging Face Transformers! 🤗

FLUX1.1 [pro] in ultra and raw modes. Images are up to 4 megapixels. Use raw mode for realism.

Hyper FLUX 8-step by ByteDance
A 7 billion parameter language model from Meta, fine tuned for chat completions

Real-ESRGAN for image upscaling on an A100

Turn a face into 3D, emoji, pixel art, video game, claymation or toy

openai/clip-vit-large-patch14 with Transformers

Unified text-to-image generation and precise single-sentence editing at up to 4K resolution

🦙 LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions

State-of-the-art image generation with top of the line prompt following, visual quality, image detail and output diversity.

Remove background from an image

Stable Diffusion fine tuned on Midjourney v4 images.

Ultra fast flux kontext endpoint

An SDXL fine-tune based on Apple Emojis

Proteus v0.2 shows subtle yet significant improvements over Version 0.1. It demonstrates enhanced prompt understanding that surpasses MJ6, while also approaching its stylistic capabilities.

Remove backgrounds from images.

Run any image through the Stable Diffusion content filter

Remove images background

multilingual text2image latent diffusion model

A 70 billion parameter language model from Meta, fine tuned for chat completions

Modify images using M-LSD line detection
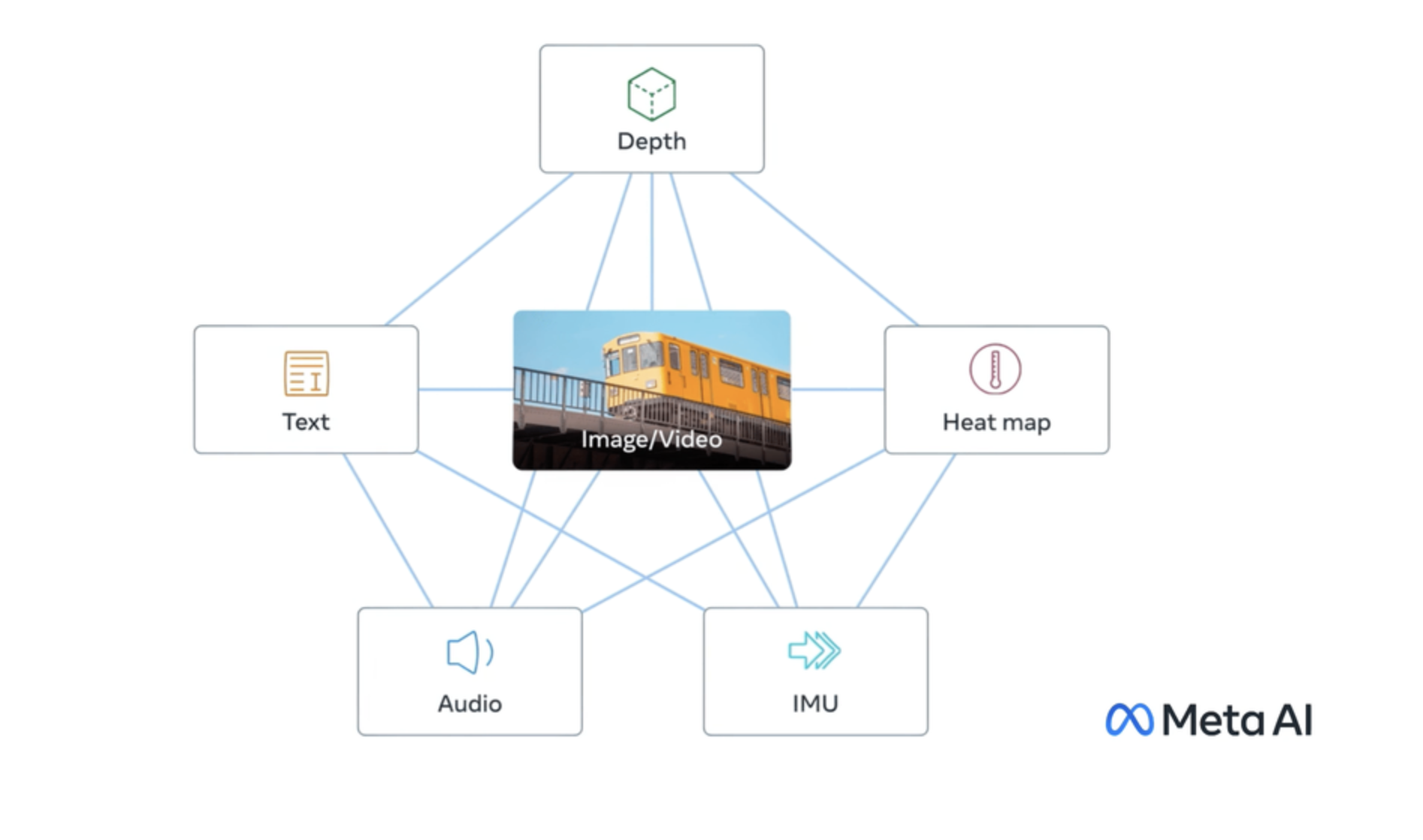
A model for text, audio, and image embeddings in one space

Anime-themed text-to-image stable diffusion model
chameleonn: one-click face swap (formerly roop)

A premium text-based image editing model that delivers maximum performance and improved typography generation for transforming images through natural language prompts

whisper-large-v3, incredibly fast, with video transcription

Create photos, paintings and avatars for anyone in any style within seconds.
Robust face restoration algorithm for old photos/AI-generated faces

Generate Pokémon from a text description

Hyper FLUX 16-step by ByteDance

Practical Image Restoration Algorithms for General/Anime Images

GFPGAN aims at developing Practical Algorithms for Real-world Face and Object Restoration

Control diffusion models

Recraft V3 (code-named red_panda) is a text-to-image model with the ability to generate long texts, and images in a wide list of styles. As of today, it is SOTA in image generation, proven by the Text-to-Image Benchmark by Artificial Analysis

Meina Mix V11 Model (Text2Img, Img2Img and Inpainting)

Run any ComfyUI workflow. Guide: https://github.com/replicate/cog-comfyui
Meta's flagship 405 billion parameter language model, fine-tuned for chat completions
A powerful AI model.

SDXL based text-to-image model applying Distribution Matching Distillation, supporting zero-shot identity generation in 2-5s. https://ai-visionboard.com

Image Restoration Using Swin Transformer

text2img model trained on LAION HighRes and fine-tuned on internal datasets

Kokoro v1.0 - text-to-speech (82M params, based on StyleTTS2)

Google's Imagen 4 flagship model

Text-to-Audio (T2A) that offers voice synthesis, emotional expression, and multilingual capabilities. Designed for real-time applications with low latency

controlnet 1.1 lineart x realistic-vision-v2.0 (updated to v5)

This is an optimised version of the hidream-l1 model using the pruna ai optimisation toolkit!

moondream2 is a small vision language model designed to run efficiently on edge devices

A background removal model enhanced with better matting

A version of flux-dev, a text to image model, that supports fast fine-tuned lora inference

Accelerated transcription, word-level timestamps and diarization with whisperX large-v3

LLaVA v1.6: Large Language and Vision Assistant (Mistral-7B)

A 13 billion parameter language model from Meta, fine tuned for chat completions

ProteusV0.3: The Anime Update

Low latency, low cost version of OpenAI's GPT-4o model

The CLIP Interrogator is a prompt engineering tool that combines OpenAI's CLIP and Salesforce's BLIP to optimize text prompts to match a given image. Use the resulting prompts with text-to-image models like Stable Diffusion to create cool art!

ZoeDepth: Combining relative and metric depth

Turbo is the fastest and cheapest Ideogram v3. v3 creates images with stunning realism, creative designs, and consistent styles

Coqui XTTS-v2: Multilingual Text To Speech Voice Cloning

Implementation of Realistic Vision v5.1 with VAE

FLUX.1-Dev LoRA Explorer (DEPRECATED Please use: black-forest-labs/flux-dev-lora)

DeepSeek-V3-0324 is the leading non-reasoning model, a milestone for open source

Add sound to video using the MMAudio V2 model. An advanced AI model that synthesizes high-quality audio from video content, enabling seamless video-to-audio transformation.

The latest Qwen-Image’s iteration with improved multi-image editing, single-image consistency, and native support for ControlNet

Implementation of Realistic Vision v5.1 to conjure up images of the potential baby using a single photo from each parent

Bilateral Reference for High-Resolution Dichotomous Image Segmentation (CAAI AIR 2024)

LLaVA v1.6: Large Language and Vision Assistant (Vicuna-13B)

Open-weight version of FLUX.1 Kontext

📖 PuLID: Pure and Lightning ID Customization via Contrastive Alignment

3 Million Runs! AI Photorealistic Image Super-Resolution and Restoration

⚡️ Blazing fast audio transcription with speaker diarization | Whisper Large V3 Turbo | word & sentence level timestamps | prompt

high-quality, highly detailed anime style stable-diffusion with better VAE
A very fast and cheap PrunaAI optimized version of Wan 2.2 A14B image-to-video

The fastest image generation model tailored for fine-tuned use

SDXL ControlNet - Canny

Professional inpainting and outpainting model with state-of-the-art performance. Edit or extend images with natural, seamless results.
A 17 billion parameter model with 16 experts

high-quality, highly detailed anime-style Stable Diffusion models
The most intelligent Claude model and the first hybrid reasoning model on the market (claude-3-7-sonnet-20250219)

@pharmapsychotic 's CLIP-Interrogator, but 3x faster and more accurate. Specialized on SDXL.

Generate music from a prompt or melody

High-quality image generation model optimized for creative professional workflows and ultra-high fidelity outputs

SDXL Inpainting by the HF Diffusers team

A text-to-image model with support for native high-resolution (2K) image generation

Anthropic's fastest, most cost-effective model, with a 200K token context window (claude-3-5-haiku-20241022)

A fast image model with state of the art inpainting, prompt comprehension and text rendering.

Playground v2.5 is the state-of-the-art open-source model in aesthetic quality

Use Kling v2.1 to generate 5s and 10s videos in 720p and 1080p resolution from a starting image (image-to-video)

Get an approximate text prompt, with style, matching an image. (Optimized for stable-diffusion (clip ViT-L/14))

Real-ESRGAN: Real-World Blind Super-Resolution

A flux lora fine-tuned on black light images

A powerful AI model.

An excellent image model with state of the art inpainting, prompt comprehension and text rendering

⚡️FLUX PuLID: FLUX-dev based Pure and Lightning ID Customization via Contrastive Alignment🎭

Reliberate v3 Model (Text2Img, Img2Img and Inpainting)

This is a language model that can be used to obtain document embeddings suitable for downstream tasks like semantic search and clustering.

This is a 3x faster FLUX.1 [schnell] model from Black Forest Labs, optimised with pruna with minimal quality loss. Contact us for more at pruna.ai

Stable diffusion fork for generating tileable outputs using v1.5 model

Fastest, most cost-effective GPT-5 model from OpenAI

Use this fast version of Imagen 4 when speed and cost are more important than quality

A reasoning model trained with reinforcement learning, on par with OpenAI o1

Minimax's first image model, with character reference support

The highest quality Ideogram v3 model. v3 creates images with stunning realism, creative designs, and consistent styles

The DeepFloyd IF model has been initially released as a non-commercial research-only model. Please make sure you read and abide to the license before using it.

FLUX.1-Schnell LoRA Explorer

An efficient, intelligent, and truly open-source language model

Like Ideogram v2, but faster and cheaper

RealVisXl V3 with multi-controlnet, lora loading, img2img, inpainting

Segment Anything with prompts

A 7 billion parameter language model from Mistral.

Determines the toxicity of text to image prompts, llama-13b fine-tune. [SAFETY_RANKING] between 0 (safe) and 10 (toxic)

A powerful AI model.

A model which generates text in response to an input image and prompt.

A video generation model that offers text-to-video and image-to-video support for 5s or 10s videos, at 480p and 720p resolution

Google's highest quality text-to-image model, capable of generating images with detail, rich lighting and beauty

Official CLIP models, generate CLIP (clip-vit-large-patch14) text & image embeddings

The LaMa (Large Mask Inpainting) model is an advanced image inpainting system designed to address the challenges of handling large missing areas, complex geometric structures, and high-resolution images.

A text-to-image model with greatly improved performance in image quality, typography, complex prompt understanding, and resource-efficiency

Realistic interior design with text and image inputs

Make stickers with AI. Generates graphics with transparent backgrounds.

FLUX.1-Dev Multi LoRA Explorer

A text-to-image model that generates high-resolution images with fine details. It supports various artistic styles and produces diverse outputs from the same prompt, thanks to Query-Key Normalization.

Simple image captioning model using CLIP and GPT-2

An experimental model with FLUX Kontext Pro that can combine two input images

Turn a face into a sticker
A 17 billion parameter model with 128 experts

A powerful AI model.

Granite-3.3-8B-Instruct is a 8-billion parameter 128K context length language model fine-tuned for improved reasoning and instruction-following capabilities.

Inpainting using RunwayML's stable-diffusion-inpainting checkpoint

Create photos, paintings and avatars for anyone in any style within seconds. (Stylization version)

A Strong Image Tagging Model with Segment Anything

Super-fast, 0.6s per image. LCM with img2img, large batching and canny controlnet
Predicts the value of a domain name.
openai/whisper with exposed settings for word_timestamps

Semantic Segmentation

powerful open-source visual language model

A powerful AI model.

Third party Fooocus replicate model

Uses pixray to generate an image from text prompt

Nonlinear Activation Free Network for Image Restoration

A deep learning approach to remove background & adding new background image

Generate 5s and 10s videos in 720p resolution at 30fps

Generate a new image from an input image with Babes 2.0

✍️✨Prompts to auto-magically relights your images

Create images of a given character in different poses

Image to image face swapping

Blip 3 / XGen-MM, Answers questions about images ({blip3,xgen-mm}-phi3-mini-base-r-v1)

Only a Matter of Style: Age Transformation Using a Style-Based Regression Model

Dream Shaper stable diffusion

An opinionated text-to-image model from Black Forest Labs in collaboration with Krea that excels in photorealism. Creates images that avoid the oversaturated "AI look".

Capture a website screenshot

Turn any image into a video
Kling 2.5 Turbo Pro: Unlock pro-level text-to-video and image-to-video creation with smooth motion, cinematic depth, and remarkable prompt adherence.

Fast, affordable version of GPT-4.1

Text-Driven Manipulation of StyleGAN Imagery

Towards Photo-Realistic Image Colorization via Dual Decoders
Create song covers with any RVC v2 trained AI voice from audio files.

Real-Time Open-Vocabulary Object Detection using the xl weights

Speech to speech with any RVC v2 trained AI voice

Deployment of Realistic vision v5.0 with xformers for fast inference

Transfer the style of one image to another

Add a watermark to your videos using the power of Replicate brought to you from your friends at FullJourney.AI

Best-in-class clothing virtual try on in the wild (non-commercial use only)
Create music for your content

Bringing Old Photos Back to Life

Open-weight inpainting model for editing and extending images. Guidance-distilled from FLUX.1 Fill [pro].

Synthesizing High-Resolution Images with Few-Step Inference
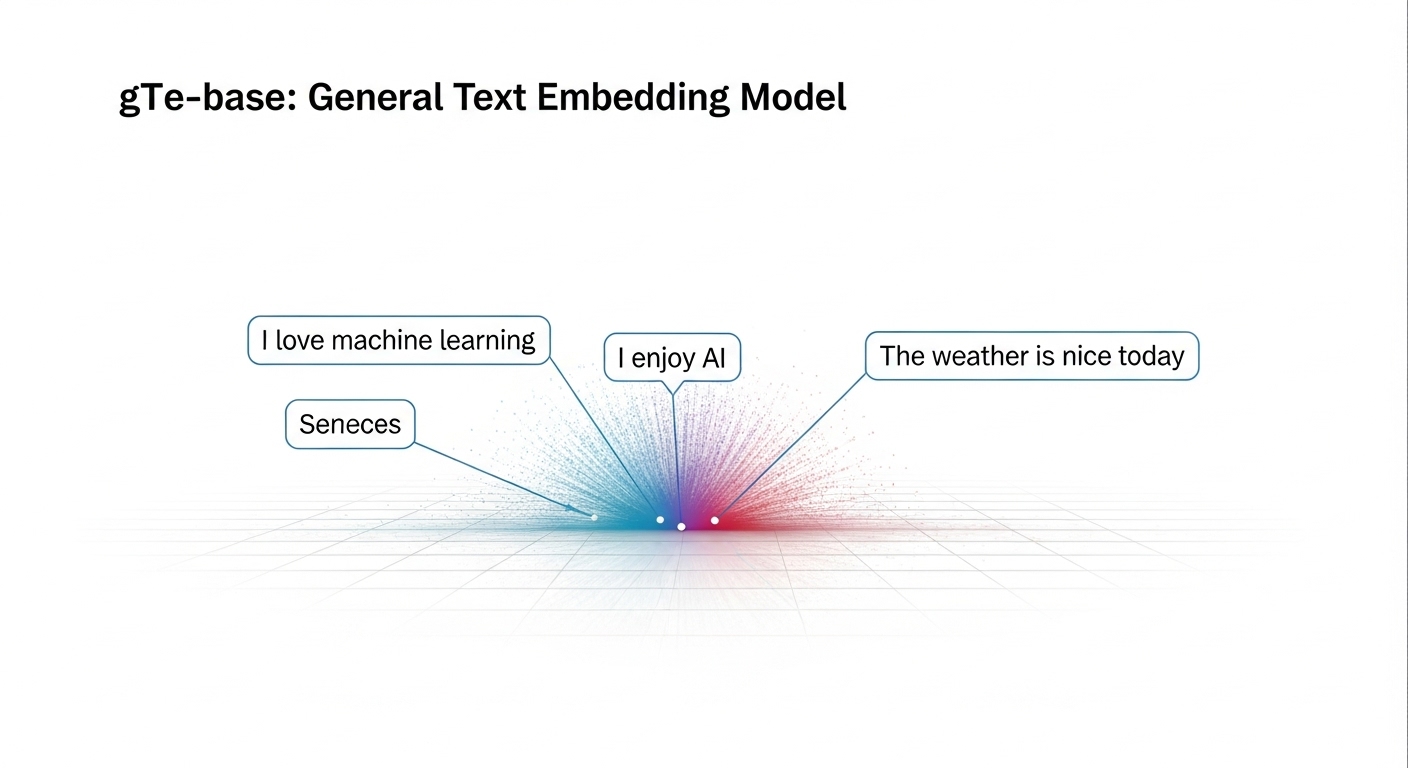
General Text Embeddings (GTE) model.

A pro version of Seedance that offers text-to-video and image-to-video support for 5s or 10s videos, at 480p and 1080p resolution

Use this ultra version of Imagen 4 when quality matters more than speed and cost

Stable Diffusion on Danbooru images

Claude Sonnet 4 is a significant upgrade to 3.7, delivering superior coding and reasoning while responding more precisely to your instructions

Embed text with Qwen2-7b-Instruct

Modify images with canny edge detection and Deliberate model twitter: @philz1337x

Text-to-Audio (T2A) that offers voice synthesis, emotional expression, and multilingual capabilities. Optimized for high-fidelity applications like voiceovers and audiobooks.

Designed to make images sharper and cleaner, Crisp Upscale increases overall quality, making visuals suitable for web use or print-ready materials.

A powerful AI model.

Stable diffusion for real-time music generation

Edit images using a prompt. This model extends Qwen-Image’s unique text rendering capabilities to image editing tasks, enabling precise text editing

An image generation foundation model in the Qwen series that achieves significant advances in complex text rendering.

Generate a new image from an input image with Stable Diffusion

Segmind Stable Diffusion Model (SSD-1B) is a distilled 50% smaller version of SDXL, offering a 60% speedup while maintaining high-quality text-to-image generation capabilities

Anything V4.5 Model (Text2Img, Img2Img and Inpainting)

batch inference for dreambooth trainings

FLUX.1-dev with XLabs-AI’s realism lora

Professional-grade image upscaling, from Topaz Labs

Make realistic images of real people instantly

'''Last update: Now supports img2img.''' SDXL Canny controlnet with LoRA support.

Third party Fooocus replicate model with preset 'realistic'

A multimodal image generation model that creates high-quality images. You need to bring your own verified OpenAI key to use this model. Your OpenAI account will be charged for usage.

A better alternative to SDXL refiners, providing a lot of quality and detail. Can also be used for inpainting or upscaling.

Edit images with human instructions

A powerful AI model.

SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation

allenai/Molmo-7B-D-0924, Answers questions and caption about images

The Qwen3 Embedding model series is specifically designed for text embedding and ranking tasks

Open-weight depth-aware image generation. Edit images while preserving spatial relationships.

Accelerated transcription, word-level timestamps and diarization with whisperX large-v3 for large audio files

Fast sdxl with higher quality

Mask prompting based on Grounding DINO & Segment Anything | Integral cog of doiwear.it

😊 Hotshot-XL is an AI text-to-GIF model trained to work alongside Stable Diffusion XL

CLIP Interrogator for SDXL optimizes text prompts to match a given image

Segments an audio recording based on who is speaking
Base version of Llama 3, a 70 billion parameter language model from Meta.

Fine-tune FLUX.1-dev using ai-toolkit

Demucs is an audio source separator created by Facebook Research.

Modify images using canny edge detection

A text-to-image model that generates high-resolution images with fine details. It supports various artistic styles and produces diverse outputs from the same prompt, with a focus on fewer inference steps

A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multi-round question answering, and creative capabilities.

Models fine-tuned from Pony-XL series.

Google's state of the art image generation and editing model 🍌🍌
Spleeter is Deezer source separation library with pretrained models written in Python and uses Tensorflow.

This model generates beautiful cinematic 2 megapixel images in 3-4 seconds and is derived from the Wan 2.2 model through optimisation techniques from the pruna package

Amazing photorealism with RealVisXL_V3.0, based on SDXL, trainable

Take a video and replace the face in it with a face of your choice. You only need one image of the desired face. No dataset, no training.

A powerful AI model.

Generate 5s and 10s videos in 1080p resolution

Video Upscaling from Topaz Labs

ControlNet QR Code Generator: Simplify QR code creation for various needs using ControlNet's user-friendly neural interface, making integration a breeze. Just key in the url !

Granite-3.1-8B-Instruct is a lightweight and open-source 8B parameter model is designed to excel in instruction following tasks such as summarization, problem-solving, text translation, reasoning, code tasks, function-calling, and more.

Jina-CLIP v2: 0.9B multimodal embedding model with 89-language multilingual support, 512x512 image resolution, and Matryoshka representations

Turn your image into a cartoon

Robust Monocular Depth Estimation

Adapt any picture of a face into another image

A llama-3 based moderation and safeguarding language model

Extract the first or last frame from any video file as a high-quality image

Make Emoji with AI.

Segment foreground objects with high resolution and matting, using InSPyReNet

Juggernaut XL v7 Model (Text2Img, Img2Img and Inpainting)

Realistic Inpainting with ControlNET (M-LSD + SEG)

Modify images using depth maps

Generate a new image given any input text with Deliberate v2

CogVLM2: Visual Language Models for Image and Video Understanding
The current model is used for graphics replacement processing

Inpainting || multi-controlnet || single-controlnet || ip-adapter || ip adapter face || ip adapter plus || No ip adapter

Base version of Llama 2 7B, a 7 billion parameter language model

Modify images using depth maps

Create Pixar poster easily with SDXL Pixar.

Create 5s-8s videos with enhanced character movement, visual effects, and exclusive 1080p-8s support. Optimized for anime characters and complex actions

A powerful AI model.

UPDATE: new upscaling algorithm for a much improved image quality. Fermat.app open-source implementation of an efficient ControlNet 1.1 tile for high-quality upscales. Increase the creativity to encourage hallucination.

Text-guided image editing model that preserves original details while making targeted modifications like lighting changes, object removal, and style conversion

Use FLUX Kontext to restore, fix scratches and damage, and colorize old photos

Colorization using a Generative Color Prior for Natural Images

Product advertising image generator

Generate 6s videos with prompts or images. (Also known as Hailuo). Use a subject reference to make a video with a character and the S2V-01 model.

OpenAI's new model excelling at coding, writing, and reasoning.

Ghiblify any image, 10x cheaper/faster than GPT 4o

Modify images using HED maps

Anthropic's most intelligent language model to date, with a 200K token context window and image understanding (claude-3-5-sonnet-20241022)

Realistic Vision V3.0 Inpainting
Thin-Plate Spline Motion Model for Image Animation

Demucs Music Source Separation

Generate a new image from an input image with Edge Of Realism - EOR v2.0

Real-ESRGAN Upscale with AI Face Correction

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks

Fastest, most cost-effective GPT-4.1 model from OpenAI

A powerful AI model.

Multi-Axis MLP for Image Processing

Join the Granite community where you can find numerous recipe workbooks to help you get started with a wide variety of use cases using this model. https://github.com/ibm-granite-community

SD1.5 Canny controlnet with LoRA support.

Photorealism with RealVisXL V3.0 Turbo based on SDXL

Generate a new image given any input text with Realistic Vision V2.0
Create tileable animations with seamless transitions

Transfer empty room into fabulous interior design

Fast, minimal port of DALL·E Mini to PyTorch
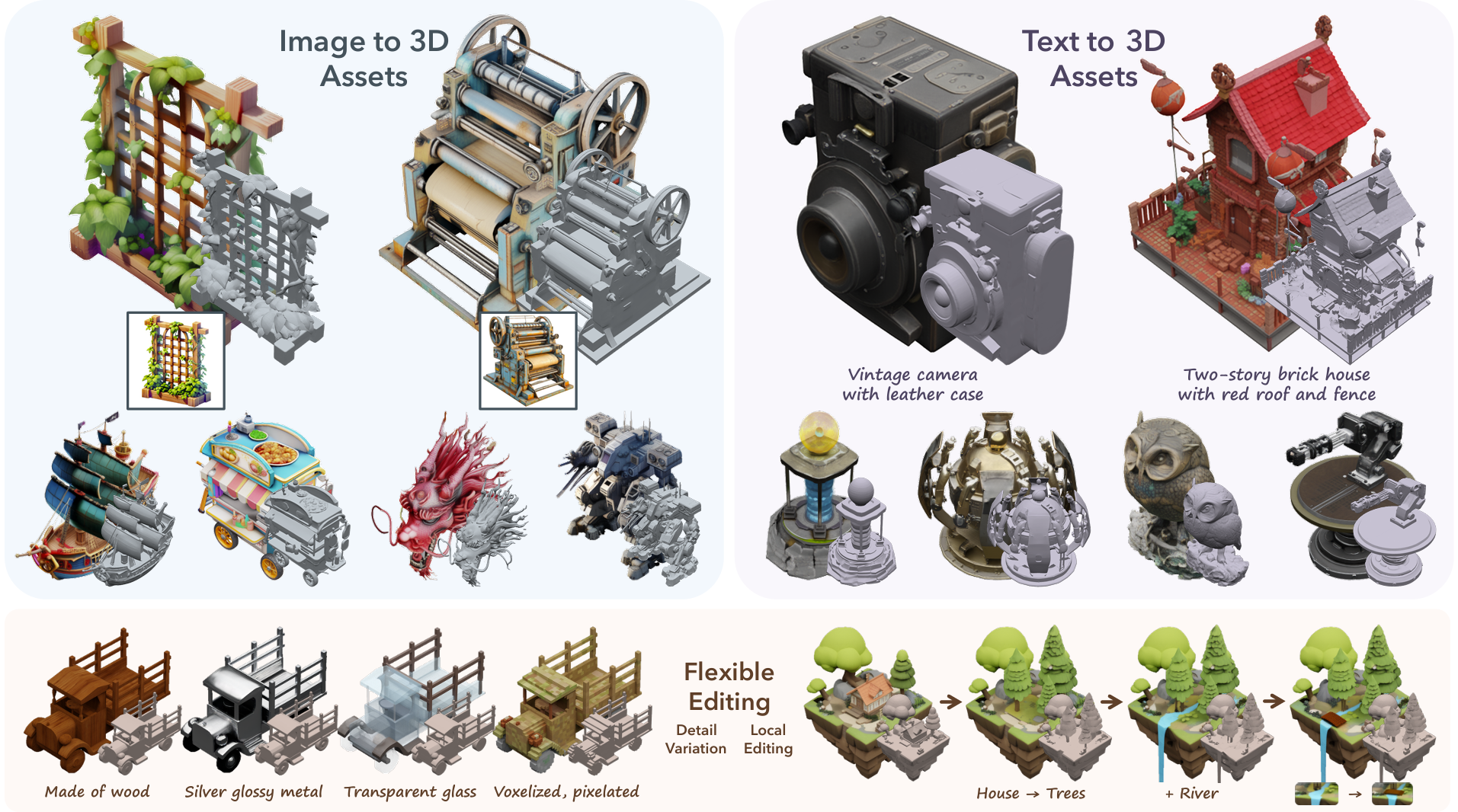
A powerful 3D asset generation model

Playground v2 is a diffusion-based text-to-image generative model trained from scratch by the research team at Playground

A faster and cheaper Imagen 3 model, for when price or speed are more important than final image quality

JoJoGAN: One Shot Face Stylization

SDXL v1.0 - A text-to-image generative AI model that creates beautiful images

Real-ESRGAN super-resolution model from ruDALL-E

Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder

Generate consistent characters from a single reference image. Outputs can be in many styles. You can also use inpainting to add your character to an existing image.

Arbitrary Neural Style Transfer

SDXL Canny controlnet with LoRA support.

A powerful AI model.

图文识别

Granite-3.2-8B-Instruct is a 8-billion parameter 128K context length language model fine-tuned for reasoning and instruction-following capabilities.

Add colours to old images

This is a 3x faster FLUX.1 [dev] model from Black Forest Labs, optimised with pruna with minimal quality loss.

Quickly generate up to 1 minute of music with lyrics and vocals in the style of a reference track

Accelerated inference for Wan 2.1 14B image to video, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation.

Use a mask to inpaint the image or generate a prompt based on the mask.

Generate a new image given any input text with DreamShaper V6

Faster version of OpenAI's flagship GPT-5 model

Runway's Gen-4 Image model with references. Use up to 3 reference images to create the exact image you need. Capture every angle.

Granite-3.0-2B-Instruct is a lightweight and open-source 2B parameter model designed to excel in instruction following tasks such as summarization, problem-solving, text translation, reasoning, code tasks, function-calling, and more.

Undi95's FlatDolphinMaid 8x7B Mixtral Merge, GGUF Q5_K_M quantized by TheBloke.

Monster Labs' control_v1p_sd15_qrcode_monster ControlNet on top of SD 1.5

Monster Labs QrCode ControlNet on top of SD Realistic Vision v5.1

Product advertising image generator using SDXL

snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance

Latent Consistency Model (LCM): SDXL, distills the original model into a version that requires fewer steps (4 to 8 instead of the original 25 to 50)

Realism XL Model (Text2Img, Img2Img and Inpainting)

Image generation, Added: inpaint_strength loras_custom_urls

🎨 Fill in masked parts of images with FLUX.1-dev 🖌️

Stable diffusion fork for generating tileable outputs

Remove background from image
Create a waveform video from audio

Professional edge-guided image generation. Control structure and composition using Canny edge detection

Train your own custom RVC model

Practical face restoration algorithm for *old photos* or *AI-generated faces* (for larger images)

Image Variations with Stable Diffusion

Like Ideogram v2 turbo, but now faster and cheaper

Quickly edit the expression of a face

Base version of Llama 2, a 70 billion parameter language model from Meta.

OpenAI's fast, lightweight reasoning model

A Llama-3.1-8B pretrained model, fine-tuned for content safety classification

high-quality, highly detailed anime style stable-diffusion

Generate a logo using text.

Phi-3-Mini-128K-Instruct is a 3.8 billion-parameter, lightweight, state-of-the-art open model trained using the Phi-3 datasets
Fine tuned to generate awesome app icons, by aistartupkit.com

Generate a new image from an input image with AbsoluteReality v1.0

Third party Fooocus replicate model with preset 'anime'

An Adversarial Approach for Picture Colorization

Modify images using normal maps

Balance speed, quality and cost. Ideogram v3 creates images with stunning realism, creative designs, and consistent styles

A powerful AI model.

Depth estimation with faster inference speed, fewer parameters, and higher depth accuracy.

Generate a new image given any input text with Dreamshaper v7
An EfficientNet for music style classification by 400 styles from the Discogs taxonomy
Animate Your Personalized Text-to-Image Diffusion Models

Use a face to make images. Uses SDXL fine-tuned checkpoints.

Recraft V3 SVG (code-named red_panda) is a text-to-image model with the ability to generate high quality SVG images including logotypes, and icons. The model supports a wide list of styles.

The Yi series models are large language models trained from scratch by developers at 01.AI.

A powerful AI model.

InstantID. ControlNets. More base SDXL models. And the latest ByteDance's ⚡️SDXL-Lightning !⚡️
The fastest Wan 2.2 text-to-image and image-to-video model

🔊 Text-Prompted Generative Audio Model

Blue Pencil XL v2 Model (Text2Img, Img2Img and Inpainting)

Zeroscope V2 XL & 576w

Design Your Hair by Text and Reference Image

BAAI's bge-en-large-v1.5 for embedding text sequences

Train your own custom Stable Diffusion model using a small set of images

Fine-grained Image Captioning with CLIP Reward

RealvisXL-v2.0 with LCM LoRA - requires fewer steps (4 to 8 instead of the original 40 to 50)

Affordable and fast images

Real-ESRGAN Video Upscaler

Generate a new image given any input text with AbsoluteReality v1.0

Implementation of SDXL RealVisXL_V2.0

sd-v2 with diffusers, test version!

OpenAI's high-intelligence chat model

A powerful AI model.

Frame Interpolation for Large Scene Motion
WhisperX transcription with inital_prompt

Professional depth-aware image generation. Edit images while preserving spatial relationships.

Latest model in the Qwen family for chatting with video and image models

InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view LRMs

Open-weight image variation model. Create new versions while preserving key elements of your original.

GPT-5 with support for structured outputs, web search and custom tools
Animating prompts with stable diffusion

XLabs v3 canny, depth and soft edge controlnets for Flux.1 Dev

Google's latest image generation model in Gemini 2.5

A powerful AI model.

Fast FLUX DEV -> Flux Controlnet Canny, Controlnet Depth , Controlnet Line Art, Controlnet Upscaler - You can use just one controlnet or All - LORAs: HyperFlex LoRA , Add Details LoRA , Realism LoRA

A powerful AI model.

A powerful AI model.

Prompt Parrot generates text2image prompts from finetuned distilgpt2

SD 1.5 trained with +124k MJv4 images by PromptHero

Generate beautiful images with simple prompts

Claude Sonnet 4.5 is the best coding model to date, with significant improvements across the entire development lifecycle

Llama2 13B with embedding output

OpenAI's Flagship GPT model for complex tasks.

Omni-Zero: A diffusion pipeline for zero-shot stylized portrait creation.

An auto-regressive causal LM created by combining 2x finetuned Llama-2 70B into one.

a dreambooth model trained on a diverse set of analog photographs
Hailuo 2 is a text-to-video and image-to-video model that can make 6s or 10s videos at 768p (standard) or 1080p (pro). It excels at real world physics.

🥯ByteDance Seed's Bagel Unified multimodal AI that generates images, edits images, and understands images in one 7B parameter model🥯

multilingual-e5-large-instruct: A multi-language text embedding model with custom query instructions.

DreamShaper is a general purpose SD model that aims at doing everything well, photos, art, anime, manga. It's designed to match Midjourney and DALL-E.

AI-driven audio enhancement for your audio files, powered by Resemble AI

Fashion Diffusion by Dreamshot

Uses pixray to generate an image from text prompt

Image Super-Resolution

flux_schnell model img2img inference

Age prediction using CLIP - Patched version of `https://replicate.com/andreasjansson/clip-age-predictor` that works with the new version of cog!

Generates game icons, For full use: appiconlab.com

A powerful AI model.

A fast image model with wide artistic range and resolutions up to 4096x4096

Ghiblify your image – ChatGPT-level quality, 10× faster and cheaper.

Multi-controlnet, lora loading, img2img, inpainting
Newest reranker model from BAAI (https://huggingface.co/BAAI/bge-reranker-v2-m3). FP16 inference enabled. Normalize param available

A powerful AI model.

Removes defocus blur in an image

Base version of Llama 2 13B, a 13 billion parameter language model

Quickly make 5s or 8s videos at 540p, 720p or 1080p. It has enhanced motion, prompt coherence and handles complex actions well.

An experimental FLUX Kontext model that can combine two input images

OmniParser is a screen parsing tool to convert general GUI screen to structured elements.

Ultra-fast, customizable speech-to-text and speaker diarization for noisy, multi-speaker audio. Includes advanced noise reduction, stereo channel support, and flexible audio preprocessing—ideal for call centers, meetings, and podcasts.

stable-diffusion-v2-inpainting
Generate Tiktok-Style Captions powered by Whisper (GPU)

High-precision image upscaler optimized for portraits, faces and products. One of the upscale modes powered by Clarity AI. X:https://x.com/philz1337x

Sound on: Google’s flagship Veo 3 text to video model, with audio
A powerful AI model.

Qwen 2: A 1.5 billion parameter language model from Alibaba Cloud, fine tuned for chat completions

A powerful AI model.

Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This version uses LLaVA-13b for captioning.

Accelerated variant of Photon prioritizing speed while maintaining quality

Realistic Vision v5.0 Image 2 Image

Morphs vector paths towards a text prompt

Generate t-shirt logos with stable-dfffusion

A powerful AI model.

Granite-3.0-8B-Instruct is a lightweight and open-source 8B parameter model is designed to excel in instruction following tasks such as summarization, problem-solving, text translation, reasoning, code tasks, function-calling, and more.

SDXL fine-tuned on photos of freshly inked tattoos

Accelerated inference for Wan 2.1 14B text to video, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation.

Image 4x super-resolution

InstantID : Zero-shot Identity-Preserving Generation in Seconds with ⚡️LCM-LoRA⚡️. Using AlbedoBase-XL v2.0 as base model.

Modify images with humans using pose detection

Bria AI's remove background model

comfy with flux model,
Generate speech from text, clone voices from mp3 files. From James Betker AKA "neonbjb".

Fast and high quality lightning model, epiCRealismXL-Lightning Hades

An image-to-video (I2V) model specifically trained for Live2D and general animation use cases

A powerful AI model.

Generate expressive, natural speech. Features unique emotion control, instant voice cloning from short audio, and built-in watermarking.

Generate a new image from an input image with DreamShaper V6

Open-weight edge-guided image generation. Control structure and composition using Canny edge detection.

NeonAI Coqui AI TTS Plugin.

Modify images using semantic segmentation

Ultimate SD Upscale with ControlNet Tile

Blind Face Restoration in the Wild

Advanced text-image comprehension and composition based on InternLM

LTX-Video is the first DiT-based video generation model capable of generating high-quality videos in real-time. It produces 24 FPS videos at a 768x512 resolution faster than they can be watched.

The Yi series models are large language models trained from scratch by developers at 01.AI.

A powerful AI model.

Artistic and high-quality visuals with improved prompt adherence, diversity, and definition

A 34 billion parameter Llama tuned for coding and conversation

FLUX Kontext max with list input for multiple images

Match facial expression using a driving image using LivePortrait as a base

SOTA Object removal, enables precise removal of unwanted objects from images while maintaining high-quality outputs. Trained exclusively on licensed data for safe and risk-free commercial use
Multi-stage text-to-video generation
A faster and cheaper version of Seedance 1 Pro

Assess the quality of an image
A language model by Google for tasks like classification, summarization, and more

Flux Content Filter - Check for public figures and copyright concerns

Uses pixray to generate an image from text prompt

Stylized Audio-Driven Single Image Talking Face Animation
Turns your audio/video/images into professional-quality animated videos

Tango 2: Use text prompts to make sound effects

Turn any text into 768-dimensional vectors for search, classification, and AI apps 🧠✨

Modify images using canny edges

Use a face to instantly make images. Uses SDXL Lightning checkpoints.

7 billion parameter version of Stability AI's language model

Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder

dreamshaper-xl-lightning is a Stable Diffusion model that has been fine-tuned on SDXL

Just some good ole beautifulsoup scrapping URL magic. (some sites don't work as they block scrapping, but still useful)

FLUX.1 Kontext[dev] image editing model for running lora finetunes

✨DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior

A powerful AI model.

Detect hate speech or toxic comments in tweets/texts

Better than SDXL at both prompt adherence and image quality, by dataautogpt3

2B instruct version of Google’s Gemma model

Color match and white balance fixes for images

Quickly change someone's hair style and hair color, powered by FLUX.1 Kontext [pro]

Generate a painting using text.

Generate a new image given any input text with Edge Of Realism - EOR v2.0

A unique fusion that showcases exceptional prompt adherence and semantic understanding, it seems to be a step above base SDXL and a step closer to DALLE-3 in terms of prompt comprehension

Generates speech from text

VideoCrafter2: Text-to-Video and Image-to-Video Generation and Editing

ProteusV0.4: The Style Update - enhances stylistic capabilities, similar to Midjourney's approach, rather than advancing prompt comprehension

LoRA Inference model with Stable Diffusion

A faster and cheaper version of Google’s Veo 3 video model, with audio
A very fast and cheap PrunaAI optimized version of Wan 2.2 A14B text-to-video

Updated Qwen3 model for instruction following

RESEARCH/NON-COMMERCIAL USE ONLY: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks

120b open-weight language model from OpenAI

CLIP Interrogator (for faster inference)

Apollo 7B - An Exploration of Video Understanding in Large Multimodal Models